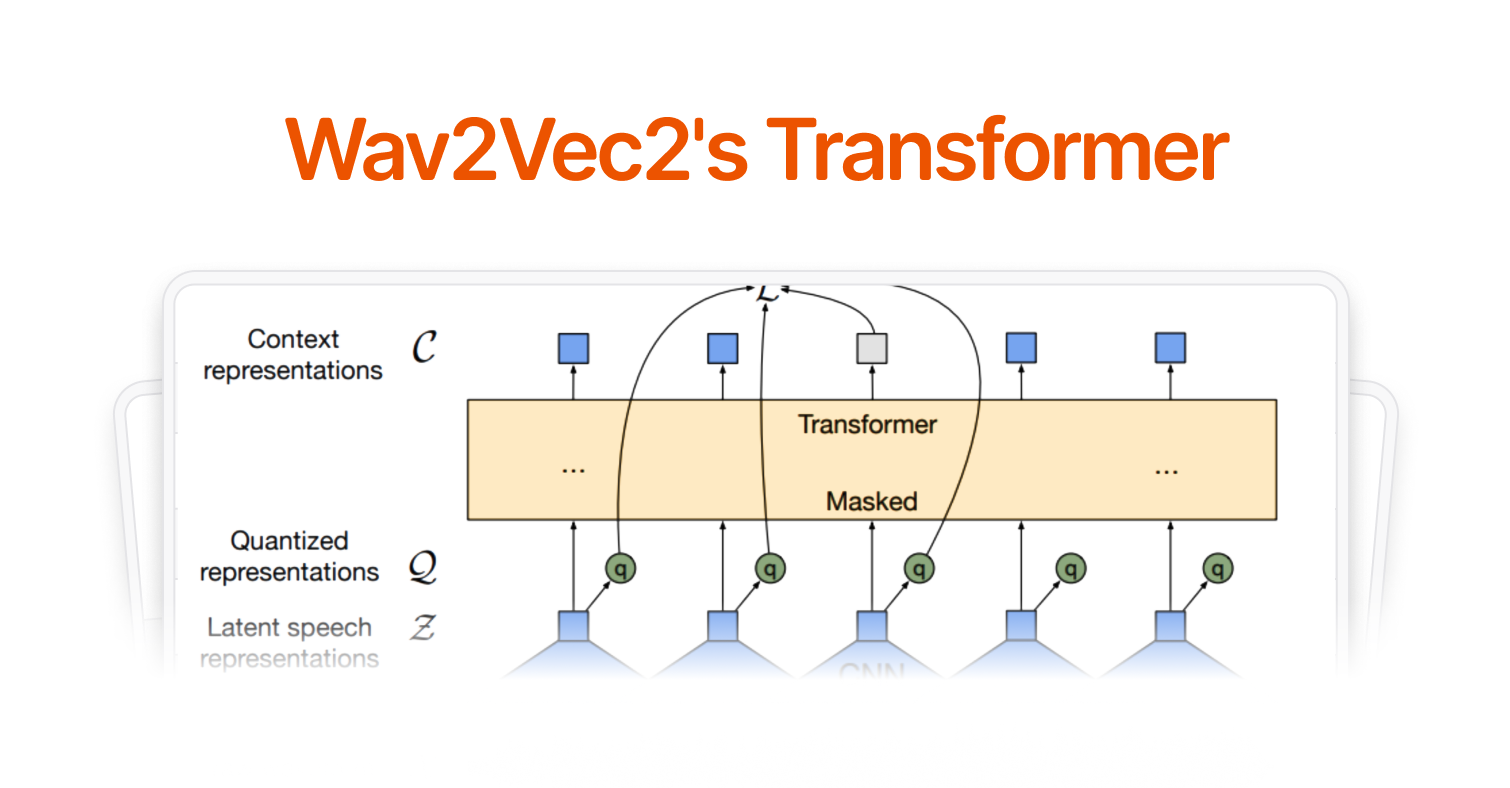
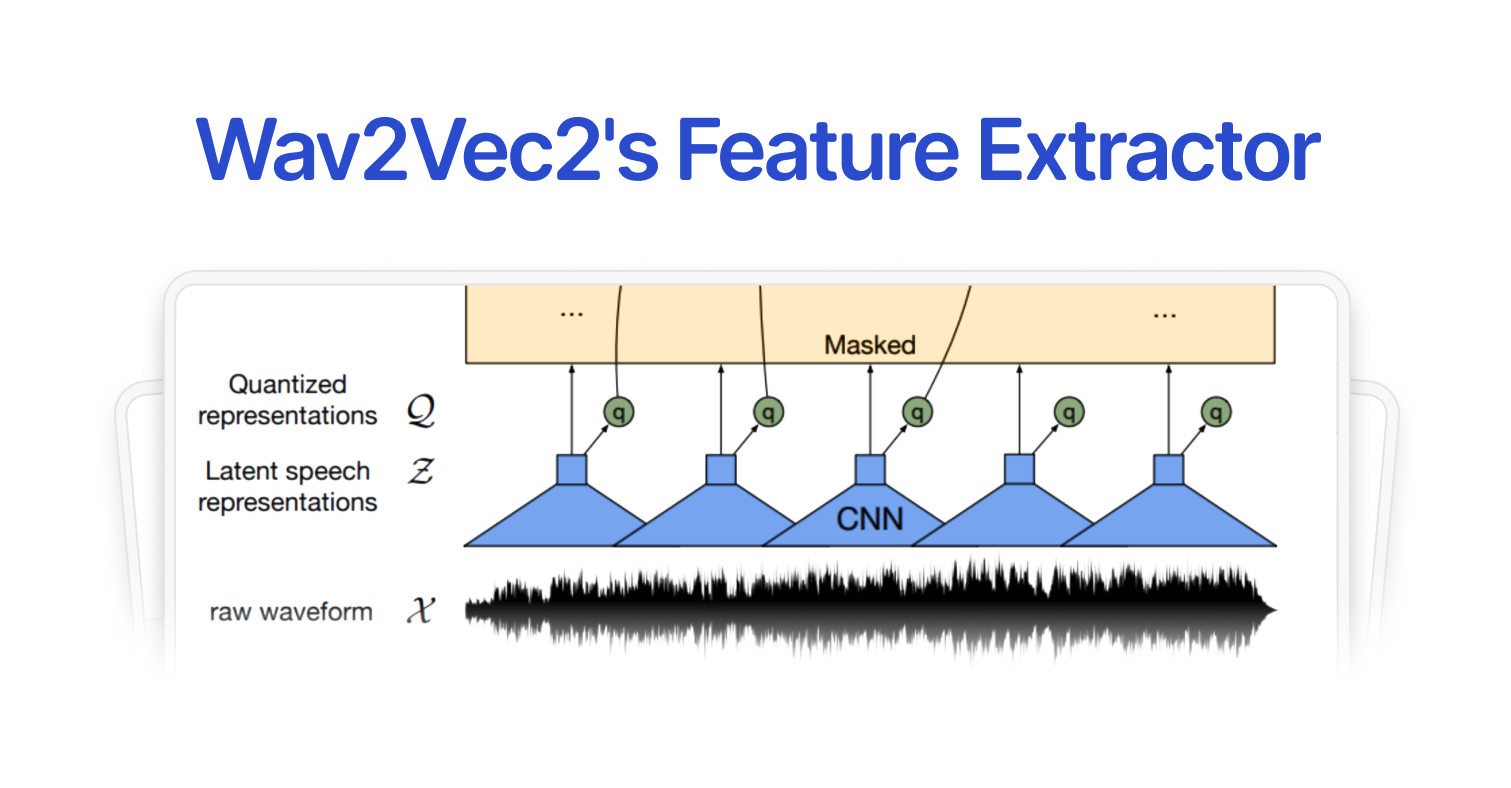
A New Look for Koel Labs



You might have noticed that we’ve given Koel Labs a fresh new look. This change is intended to better align us with our mission of pioneering inclusive speech technology, with our goals as a research-focused startup, and with our belief in openly sharing our work.
Announcement